
Task 1: Punctuation restoration from read text
Motivation
Speech transcripts generated by Automatic Speech Recognition (ASR) systems typically do not contain any punctuation or capitalization. In longer stretches of automatically recognized speech, the lack of punctuation affects the general clarity of the output text [1]. The primary purpose of punctuation (PR) and capitalization restoration (CR) as a distinct natural language processing (NLP) task is to improve the legibility of ASR-generated text, and possibly other types of texts without punctuation. Aside from their intrinsic value, PR and CR may improve the performance of other NLP aspects such as Named Entity Recognition (NER), part-of-speech (POS) and semantic parsing or spoken dialog segmentation [2, 3]. As useful as it seems, It is hard to systematically evaluate PR on transcripts of conversational language; mainly because punctuation rules can be ambiguous even for originally written texts, and the very nature of naturally-occurring spoken language makes it difficult to identify clear phrase and sentence boundaries [4,5]. Given these requirements and limitations, a PR task based on a redistributable corpus of read speech was suggested. 1200 texts included in this collection (totaling over 240,000 words) were selected from two distinct sources: WikiNews and WikiTalks. Punctuation found in these sources should be approached with some reservation when used for evaluation: these are original texts and may contain some user-induced errors and bias. The texts were read out by over a hundred different speakers. Original texts with punctuation were forced-aligned with recordings and used as the ideal ASR output. The goal of the task is to provide a solution for restoring punctuation in the test set collated for this task. The test set consists of time-aligned ASR transcriptions of read texts from the two sources. Participants are encouraged to use both text-based and speech-derived features to identify punctuation symbols (e.g. multimodal framework [6]). In addition, the train set is accompanied by reference text corpora of WikiNews and WikiTalks data that can be used in training and fine-tuning punctuation models.
Task description
The purpose of this task is to restore punctuation in the ASR recognition of texts read out loud.
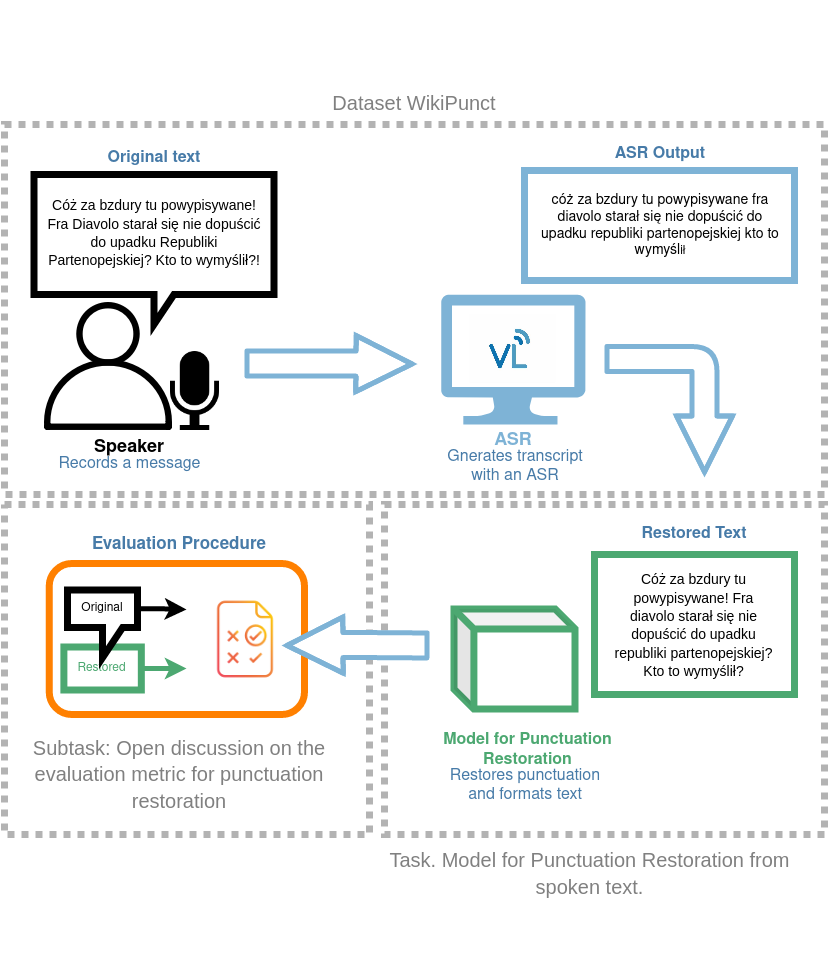
Dataset – WikiPunct
WikiPunct is a crowdsourced text and audio data set of Polish Wikipedia pages read out loud by Polish lectors. The dataset is divided into two parts:conversational(WikiTalks)and information (WikiNews). Over a hundred people were involved in the production of the audio component. The total length of audio data reaches almost thirty-six hours, including the test set. Steps were taken to balance the male-to-female ratio.
WikiPuncthas over thirty-two thousand texts and 1200 audio files, one thousand in the training set and two hundred in the test set. There is a transcript of automatically recognized speech and force-aligned text for each text. The details behind the data format and evaluation metrics are presented below in the respective sections.
Statistics:
- Text:
- ver thirty-two thousand texts; WikiNews ca. 15,000, WikiTalks ca. 17,000;
- Audio:
- Selection procedure:
- randomly selected WikiNews (80% that is equal 800 entries for the training set) with the word count above 150 words and smaller than 300 words;
- randomly selected WikiTalks (20%) with word the count above 150 words but smaller than 300 words and at least one question mark
- Data set split
- Training data: 1000 recordings
- Test data: at 274 recordings
- Speakers:
- Polish male: 51 speakers, 16.7 hours of speech
- Polish female: 54 speakers, 19 hours of speech
- Selection procedure:
Punctuation for raw text:
| symbol | mean | median | max | sum | included | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| fullstop | . | 12.44 | 7.0 | 1129.0 | 404 378 | yes | |||||||
| comma | , | 10.97 | 5.0 | 1283.0 | 356 678 | yes | |||||||
| question_mark | ? | 0.83 | 0.0 | 130.0 | 26 879 | yes | |||||||
| exclamation_mark | ! | 0.22 | 0.0 | 55.0 | 7 164 | yes | |||||||
| hyphen | - | 2.64 | 1.0 | 363.0 | 81 190 | yes | |||||||
| colon | : | 1.49 | 0.0 | 202.0 | 44 995 | yes | |||||||
| ellipsis | … | 0.27 | 0.0 | 60.0 | 8 882 | yes | |||||||
| semicolon | ; | 0.13 | 0.0 | 51.0 | 4 270 | no | |||||||
| quote | " | 3.64 | 0.0 | 346.0 | 116 874 | no | |||||||
| words | 169.50 | 89.0 | 17252.0 | 5 452 032 | - |
The dataset is divided into two parts: conversational (WikiTalks) and information (WikiNews).
Part 1. WikiTalks
Data scraped from Polish Wikipedia Talk pages. Talk pages, also known as discussion pages, are administration pages with editorial details and discussions for Wikipedia articles.. Talk pages were scrapped from the web using a list of article titles shared alongside Wikipedia dump archives.
Wikipedia Talk pages serve as conversational data. Here, users communicate with each other by writing comments. Vocabulary and punctuation errors are expected. This data set covers 20% of the spoken data.
Example:
- wikitalks001948: Cóż za bzdury tu powypisywane! Fra Diavolo starał się nie dopuścić do upadku Republiki Partenopejskiej? Kto to wymyślił?! Człowiek ten był jednym z najżarliwszych wrogów francuskiej okupacji, a za zasługi w wypędzeniu Francuzów został mianowany pułkownikiem w królewskiej armii z prawdziwie królewską pensją. Bez niego wyzwolenie, nazywać to tak czy też nie, północnej części królestwa byłoby dużo trudniejsze, bo dysponował siłą kilku tysięcy sprawnych w boju i umiejętnie wziętych w karby rzezimieszków. Toteż armia Burbonów nie pokonywała go, jak to się twierdzi w artykule, lecz ściśle współpracowała. Redaktorów zachęcam do jak najszybszej korekty artykułu, bo aktualnie jest obrazą dla ambicji Wikipedii. 91.199.250.17
- wikitalks008902: Stare wątki w dyskusji przeniosłem do archiwum. Od prawie roku dyskusja w nich nie była kontynuowana. Sławek Borewicz
Part 2. WikiNews
Wikinews is a free-content news wiki and a project of the Wikimedia Foundation. The site works through collaborative journalism. The data was scraped directly from wikinews dump archive. The overall text quality is high, but vocabulary and punctuation errors may occur. This data set covers 80% of the spoken data.
Example:
- wikinews222361: Misja STS-127 promu kosmicznego Endeavour do Międzynarodowej Stacji Kosmicznej została przełożona ze względu na wyciek wodoru. Podczas procesu napełniania zewnętrznego zbiornika paliwem, część ciekłego wodoru przemieniła się w gaz i przedostała się do systemu odpowietrzania. System ten jest używany do bezpiecznego odprowadzania nadmiaru wodoru z platformy startowej 39A do Centrum Lotów Kosmicznych imienia Johna F. Kennedy'ego. Początek misji miał mieć miejsce dzisiaj, o godzinie 13:17. Ze względu jednak na awarię, najbliższa możliwa data startu wahadłowca to środa 17 czerwca, jednak na ten dzień NASA na Przylądku Canaveral zaplanowana wystrzelenie sondy kosmicznej Lunar Reconnaissance Orbiter. Misja może być zatem opóźniona do 20 czerwca, który jest ostatnią możliwą datą startu w tym miesiącu. W niedzielę odbędzie się spotkanie specjalistów NASA, na którym zostanie ustalona nowa data startu i dalszy plan misji STS-127.
Data format
We provide two types of data: text and audio data. Text data is provided in JSON and CSV formats (see Text data section). For Audio data we provide audio files as WAV files and transcripts with timestamps and force-alignment (see Force-alignment.section).
Text data
Text data is saved in JSON and CSV format. The name of each file corresponds to the document identifier with the corresponding extension. Files in JSON format have the following schema:
{
"type": "object",
"properties": {
"title": {
"type": "string"
},
"words": {
"type": "array",
"items": [{
"type": "object",
"properties": {
"word": {
"type": "string"
},
"punctuation": {
"type": "string"
},
"space_after": {
"type": "boolean"
}
},
"required": ["word", "punctuation", "space_after"]
}]
}
}
}Field description:
- "title" - the ID number of a single wiki news or talk
- "words" - used to keep a list of words and punctuation marks in a single wiki news or talk
- "word"- used to store a single word or punctuation mark that is not predicted in the task.
- "punctuation" - used to store a punctuation mark after the "word". Leave empty if there is no punctuation after. List of evaluated punctuation marks is in the Evaluation Procedure Section.
- "space_after" - set True if the space after a word should apply.
CSV files contain a header that explains the meaning of each field. These are "word", "punctuation" and "space_after". The delimiter is a comma. The meaning of the individual fields is analogous to the JSON format.
Forced-aligned transcriptions
We use force-aligned transcriptions of the original texts to approximate ASR output. Files in the .clntmstmp format contain forced-alignment of the original text together with the audio file read out by a group of volunteers. The files may contain errors resulting from incorrect reading of the text (skipping fragments, adding words missing from the original text) and alignment errors resulting from the configuration of the alignment tool for text and audio files. The configuration targeted Polish; names from foreign languages may be poorly recognised, with the word duration equal to zero (start and end timestamps are equal). Data is given in the following format:
(timestamp_start,timestamp_end) word
…
where is a symbol of the end of recognition.
Example:
(990,1200) Rosja
(1230,1500) zaczyna
(1590,1950) powracać
(1980,2040) do
(2070,2400) praktyk
(2430,2490) z
(2520,2760) czasów
(2820,3090) zimnej
(3180,3180) wojny.
(3960,4290) Rosjanie
(4380,4770) wznowili
(4860,5070) bowiem
(5100,5160) na
(5220,5430) stałe
(5520,5670) loty
(5760,6030) swoich
(6120,6600) bombowców
(6630,7230) strategicznych
(7350,7530) poza
(7590,7890) granice
(8010,8010) kraju.
(8880,9300) Prezydent
(9360,9810) Władimir
(9930,10200) Putin
(10650,10650) wyjaśnił,
(10830,10920) iż
(10980,11130) jest
(11160,11190) to
(11220,11520) odpowiedź
(11550,11640) na
(11670,12120) zagrożenie
(12240,12300) ze
(12330,12570) strony
(12660,12870) innych
(13140,13140) państw.
Evaluation procedure
Baseline results will be provided in final evaluation.
Punctuation
During the task the following punctuation marks will be evaluated:
| Punctuation mark | symbol |
|---|---|
| fullstop | . |
| comma | , |
| question mark | ? |
| exclamation mark | ! |
| hyphen | - |
| colon | : |
| ellipsis | … |
| blank (no punctuation) |
Submission format
Results are to be submitted in a JSON file with the format matching the input data. Files with results will be tested against the gold standard annotations kept in the file with the matching text ID in the file name.
Example result directory structure
For a given poleval_text.test.tar.gz data set with has the following structure:
test/
json/
wikitalks109264.json
wikitalks0017548.json
wikitalks0017518.json
wikitalks0017499.json
…
csv/
wikitalks109264.csv
wikitalks0017548.csv
wikitalks0017518.csv
wikitalks0017499.csv
…This is the directory structure for poleval_wav.test.tar.gz :
poleval_final_dataset_wav/
test/
wikitalks109264.wav
wikitalks0017548.wav
wikitalks0017518.wav
wikitalks0017499.wav
...Here is the directory structure for poleval_fa.test.tar.gz :
poleval_final_dataset/
test/
wikitalks109264.clntmstmp
wikitalks0017548.clntmstmp
wikitalks0017518.clntmstmp
wikitalks0017499.clntmstmp
...The correct submission format should be:
system_response/
wikitalks109264.json
wikitalks0017548.json
wikitalks0017518.json
wikitalks0017499.json
...Schema validation
Use jsonschema to run a sanity check against the file with the results:https://pypi.org/project/jsonschema/
$ jsonschema -i result.json result.schemaFor multiple files:
$ ls result/*.json | xargs -I{} jsonschema -i {} result.schemaEvaluation Script
Evaluation script will be provided on the task's page.
$ python3 evaluate.py gold_directory system_directoryMetrics
Final results are evaluated in terms of precision, recall, and F1 scores for predicting each punctuation mark separately. Submissions are compared with respect to the weighted average of F1 scores for each punctuation sign.
Per-document score:
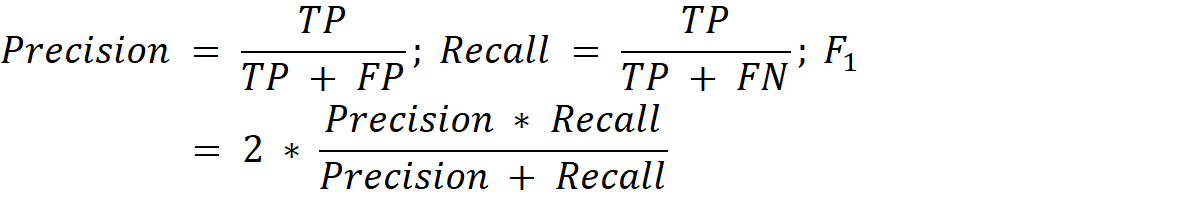
Global score per punctuation sign p:

Final scoring metric calculated as weighted average of global scores per 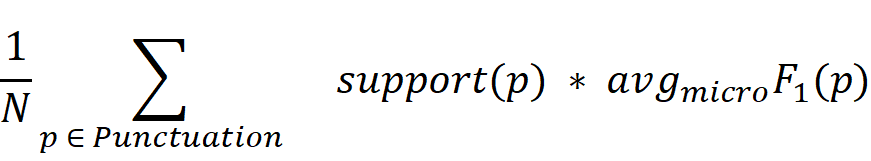
We would like to invite participants to discussion about evaluation metrics, taking into account such factors as:
- ASR and Forced-Alignment errors,
- inconsistencies among annotators,
- impact of only slight displacement of punctuation,
- assigning different weights to different types of errors.
Downloads
Data has been published in the following repository (https://github.com/poleval/2021-punctuation-restoration).
Gold-standard test data annotation has been published in the "secret" branch (https://github.com/poleval/2021-punctuation-restoration/tree/secret/test-D).
References
- Yi, J., Tao, J., Bai, Y., Tian, Z., & Fan, C. (2020). Adversarial transfer learning for punctuation restoration. arXiv preprint arXiv:2004.00248.
- Nguyen, Thai Binh, et al. "Improving Vietnamese Named Entity Recognition from Speech Using Word Capitalization and Punctuation Recovery Models." Proc. Interspeech 2020 (2020): 4263-4267.
- Hlubík, Pavel, et al. "Inserting Punctuation to ASR Output in a Real-Time Production Environment." International Conference on Text, Speech, and Dialogue. Springer, Cham, 2020.
- Sirts, Kairit, and Kairit Peekman. "Evaluating Sentence Segmentation and Word Tokenization Systems on Estonian Web Texts." Human Language Technologies–The Baltic Perspective: Proceedings of the Ninth International Conference Baltic HLT 2020. Vol. 328. IOS Press, 2020.
- Wang, Xueyujie. "Analysis of Sentence Boundary of the Host's Spoken Language Based on Semantic Orientation Pointwise Mutual Information Algorithm." 2020 12th International Conference on Measuring Technology and Mechatronics Automation (ICMTMA). IEEE, 2020.
- Sunkara, Monica, et al. "Multimodal Semi-supervised Learning Framework for Punctuation Prediction in Conversational Speech." arXiv preprint arXiv:2008.00702 (2020).